サーバとドメインを移転したお客さんのサイトが、全然インデックスされないとの連絡をいただきました。
ドメインも変わってるのだから、それはそうだろうとも思ってたんですが、移転したのは3か月くらい前だし、おかしいってことで調べてみました。
あやしいところでは、robots.txtやHTMLのmetaタグでクロール禁止設定しているあたりですが、robots.txtはそもそもないし、HTMLのmetaタグもほぼ無いに等しいほどシンプル。
リダイレクトも旧サーバ・旧ドメインから301できっちり転送しているので問題ない。
仕方ないので、Search Consoleを設定して調べてみたところ、下図のエラーが出てました。
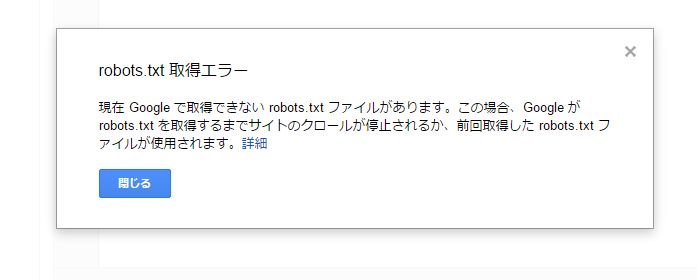
(Search Consoleの左メニュー>クロール>robots.txtテスターを開くと出てきたエラー)
現在 Google で取得できない robots.txt ファイルがあります。この場合、Google が robots.txt を取得するまでサイトのクロールが停止されるか、前回取得した robots.txt ファイルが使用されます。
robots.txtなんてファイルは作ってないし、実際サーバ上にも無いし、おかしいなと思ってrobots.txtにブラウザからアクセスしてみたら、htaccessのリライトルールのせいで、404エラーでもない変なエラーページが開いてしまいました。
そして下の記事を発見。
robots.txtがこんなに重要だったとは。。。身をもって知りました
なんとまあ、robots.txtは存在してちゃんと設定されているか、または無いなら404エラーで返さないと、Googleはインデックスしてくれなくなるらしい。
正直、インデックスされないように設定することのほうが少ないため、robots.txtなんてあんまり気にしたことありませんでした。(通常は無いなら無いで404になるし)
気をつけねば。